

TL;DR
Relying solely on Kubernetes Namespaces or vClusters for multi-tenant isolation in GPU clouds is risky — especially when hosting untrusted or external workloads.
In September 2024, Wiz discovered a critical NVIDIA Container Toolkit vulnerability (CVE-2024-0132) that allowed GPU containers to escape soft isolation and gain root access to the host. This flaw impacted over one-third of GPU-enabled environments and exposed the limits of Kubernetes-based isolation.
Soft isolation ≠ secure isolation. For environments like Neoclouds, NVIDIA Cloud Partners (NCPs), or regulated industries, only hard or hybrid isolation strategies — such as dedicated Kubernetes clusters, MIG-based GPU partitioning, VPCs, VxLAN, VRFs, KVM virtualization, IB P-KEY, and NVLink partitioning — can protect against container escapes.
Tools like aarna.ml GPU Cloud Management Software (CMS) help enforce hard multi-tenancy across infrastructure layers, providing the protection modern AI workloads demand.
Context
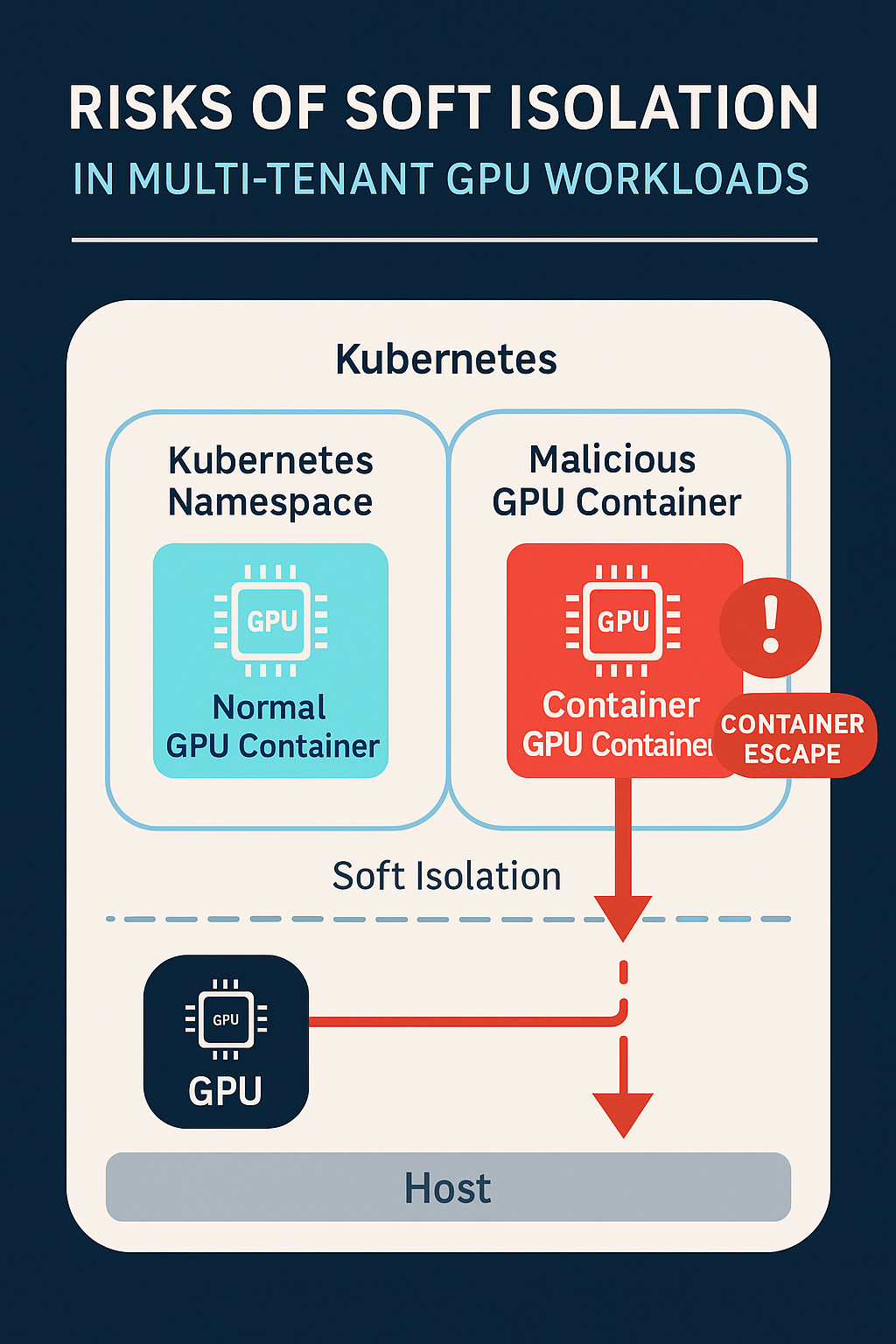
When building a multi-tenant GPU cloud, it's common to rely on Kubernetes-native tools like Namespaces or vClusters for tenant isolation. This “soft isolation” approach offers ease of deployment and simplicity — but it carries serious security risks in GPU-accelerated environments.
Soft Isolation ≠ Security Isolation
Soft isolation assumes that tenants can safely share the same Kubernetes control plane, node kernel, and container runtime. But when it comes to multi-tenant GPU workloads, this assumption breaks down fast — and can open the door to container escapes, privilege escalation, and cross-tenant compromise.
This isn’t just theoretical.
Real-World Example: The NVIDIA GPU Container Vulnerability
In September 2024, security researchers at Wiz discovered a critical vulnerability — CVE-2024-0132 — in the NVIDIA Container Toolkit (≤ v1.16.1), a core component used to enable GPU access for Docker, containerd, and CRI-O containers.
Here’s what went wrong:
- The bug was a time-of-check/time-of-use (TOCTOU) race condition.
- It allowed a malicious GPU container to mount the host filesystem using NVIDIA’s container runtime hooks.
- Once the container had access to the host filesystem, it could interact with the container runtime socket (e.g., containerd.sock or docker.sock) and gain root-level access to the host.
- This effectively allowed a tenant to escape their container sandbox and compromise the entire node.
The vulnerability was widespread. Wiz estimated that over one-third of cloud GPU environments — across AWS, Azure, GCP, and on-prem systems — were running the vulnerable software. Kubernetes clusters using the NVIDIA GPU Operator ≤ v24.6.1 were especially affected.
Critically, this vulnerability bypassed all protections offered by Kubernetes Namespaces or vClusters. Even if workloads were logically isolated at the K8s level, any tenant with the ability to run a malicious GPU container could break out and attack the host.
What This Means for GPU Multi-Tenancy
This incident underscores a hard truth: soft isolation is not sufficient in environments where untrusted or external tenants run GPU workloads. Kubernetes Namespaces and vClusters only provide logical segmentation — they don’t protect against kernel-level or runtime-level exploits.
For Neoclouds, NVIDIA Cloud Partners (NCPs), or regulated enterprises, soft isolation leaves the door wide open. A single misconfigured container or a compromised customer workload could escalate into a full infrastructure breach.
What You Should Be Doing Instead
To protect against these risks, multi-tenant GPU clouds must adopt hard or hybrid isolation, including:
- Dedicated Kubernetes clusters or node pools per tenant
- CPU partitioning via KVM (virtualization) or bare-metal allocation
- GPU resource partitioning via MIG or bare-metal allocation
- Spectrum-X or other Ethernet network segmentation using VPCs or VxLANs
- Infiniband isolation using P-KEYS
- NVLink partitioning
- Storage-level isolation using VRFs and tenant-specific volumes
- Runtime controls that avoid shared container runtimes for untrusted workloads
- Use of CDI (Container Device Interface) mode instead of NVIDIA’s older hooks (CDI is not affected by CVE-2024-0132)
Additionally, any GPU cloud environment should now be running the latest version of NVIDIA Container Toolkit and GPU Operator.
While deploying a dedicated, multi-node Kubernetes cluster is the gold standard for large production tenants, this model is not always cost-effective for smaller teams, university labs, or development workloads. To address this, lightweight, dedicated Kubernetes clusters using efficient, fully compliant distributions like K3s or MicroK8s could also be considered. These clusters are deployed within a single virtual machine, providing a complete, self-contained environment with its own dedicated kernel and control plane, while physical GPUs are attached via passthrough.
Bottom Line
Soft isolation is fine — until it isn’t. In GPU-accelerated environments, especially those involving multi-tenancy, the risks are too high to depend solely on Kubernetes constructs like Namespaces or vClusters.
Real-world vulnerabilities like CVE-2024-0132 show that container escapes are not just possible — they’re happening. If you’re serving customers, partners, or even internal departments with access to GPU workloads, you need real, infrastructure-level isolation.
The good news? With tools like aarna.ml GPU CMS, you can build secure, tenant-isolated GPU clouds that automatically configure isolation across compute, storage, networking, VPC, NVLink, Infiniband, and GPUs — without taking on all the complexity yourself.
Want to learn more?
Reach out to us at info@aarna.ml — we’d love to help you build a secure, multi-tenant GPU cloud.



