


Introduction: The Growing Need for Edge Inference
All AI is not created equal. While centralized inference serves some use-cases well where long thinking times are acceptable, new use cases such as physical AI, real-time
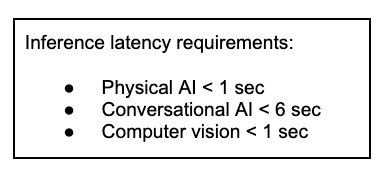
agentic AI chatbots, digital avatars doing real time dialog, and computer vision require faster response times. It is not just about network latency, but compute latency becomes important, mandating computation closer to data sources, and lower bandwidth usage across the network in order to scale cost effectively. These applications can’t tolerate the latency of round trips to centralized data centers nor can they afford the cost of constantly transferring large volumes of data. Instead, they require inference that is geographically distributed, dynamically orchestrated, and tightly optimized for latency and bandwidth. Equally important is an Agentic AI optimized compute architecture at the edge for the best performance per token, per watt.
This is fueling a surge in demand for distributed inference infrastructure—capable of running AI models across clusters of GPUs residing at regional data centers and edge sites, while maintaining cloud-like flexibility and scale. The distributed inference market is poised for exceptional growth between 2025 and 2030, with projections indicating an expansion from USD 106.15 billion to USD 254.98 billion at a CAGR of 19.2%.1
Why NVIDIA MGX Servers Are a Game-Changer for Edge Inference
NVIDIA MGX™ servers, based on a modular reference design, can be used for a wide variety of use cases, from compute-intensive datacenter to edge workloads. MGX provides a new standard for modular server design by improving ROI and reducing time to market and is especially suited to distributed inference. Some of the reasons for this are:
- Modular design allows core and edge sites to scale from 1 RU to multiple racks of servers
- High performance per watt allows maximum GPU compute capacity to be deployed at the distributed inference site
- Integration with NVIDIA Cloud Functions (NVCF) and NVIDIA NIM, both included in the NVIDIA AI Enterprise suite, providing access to a large number of vertically oriented models and solutions
When combined with NVIDIA Spectrum-X™ Ethernet networking platform for AI, customers can extract the full performance of the underlying GPUs.
The NVIDIA Spectrum™-X Ethernet platform is designed specifically to improve the performance and efficiency of Ethernet-based AI infrastructure powering AI factories and clouds. This breakthrough technology achieves superior AI networking performance, along with consistent, predictable performance in multi- tenant environments. Spectrum-X is built on network innovations powered by the tight coupling of the NVIDIA Spectrum-X Ethernet switch and NVIDIA® SuperNICs. Spectrum-X network optimizations reduce runtimes of massive transformer-based generative AI models and deliver faster time to insight.
Challenges in Building an Edge Inference Stack
While MGX servers along with Spectrum-X and NVIDIA AI Enterprise offer an integrated solution stack, distributed inference presents a number of infrastructure challenges for a GPU-as-a-Service (GPUaaS) provider:
- Managing multiple sites: Distributed GPUaaS providers typically have multiple sites that are often in light-out environments. The infrastructure consisting of compute, storage, networking, and WAN gateways has to be managed remotely with the lowest possible OPEX.
- Managing isolation between multiple tenants (users): Distributed GPU sites have multiple tenants that demand the highest level of security between tenants.
- Matching workloads the correct GPU site: Workloads have to be mapped to the appropriate site for latency, bandwidth, compliance, or data gravity reasons(edge or core).
- Maximizing utilization: Given the high cost of GPUs, utilization has to be as close to 100% as possible at all times. The GPUaaS provider requires dynamic scaling of tenant infrastructure for transactional jobs, efficient job scheduling for batch jobs, and making capacity available within NVIDIA Cloud Functions (NVCF) or similar services.
The Need for Secure, Dynamic Tenancy and Isolation in AI Workloads
The above challenges require a secure and dynamic tenancy software layer for distributed inference. The ideal software solution must offer:
- Zero touch management of the underlying hardware infrastructure potentially across 10,000s edge and core sites to slash OPEX
- isolation between tenants for security and compliance
- Dynamic resource scaling for maximizing GPU utilization
- Registration of underutilized resources with NVCF for maximizing GPU utilization
Being AI-RAN Ready
A special non-AI/ML workload that is also relevant in this discussion pertains to 5G/6G mobile networks. A key component of the 5G/6G stack is the radio area network (RAN) software that connects mobile devices to the core network, utilizing sophisticated modulation technologies that enable wireless connectivity with increased speeds, capacity, and efficiency. The RAN software is an edge workload that benefits from GPU acceleration. For this reason, it makes sense to run the 5G/6G RAN software on the same distributed inference infrastructure described above. Rather than require dedicated hardware that is often grossly underutilized in the 20%-30% range, unified GPU hardware for AI-and-RAN improves the effective hardware utilization.
Introducing aarna.ml GPU Cloud Management Software
The aarna.ml GPU Cloud Management Software (CMS) provides the following functionality:

- On-demand isolation spanning CPU, GPU, network, storage, and the WAN gateway
- Bare metal, virtual machine, or container instances
- Automated infrastructure management for tenants with scale-out and scale-in
- Admin functionality to discover, observe, and manage the underlying hardware (compute, networking, storage) across 10,000s of sites
- Billing and User management with RBAC
- Integration with open source (Ray, vLLM) or 3rd party PaaS (Red Hat OpenShift and more)
- Integration with NVIDIA Cloud Functions (NVCF) to monetize unused capacity
- Centralized Management for managing and orchestrating multiple Edge locations
Reference Architecture: NVIDIA + aarna.ml for Edge Inference
The aarna.ml GPU CMS when coupled with NVIDIA MGX, Spectrum-X, and NVIDIA AI Enterprise solves the above-listed problems for GPUaaS providers. The high-level topology diagram for the distributed inference reference architecture (at each Edge site) is shown below.
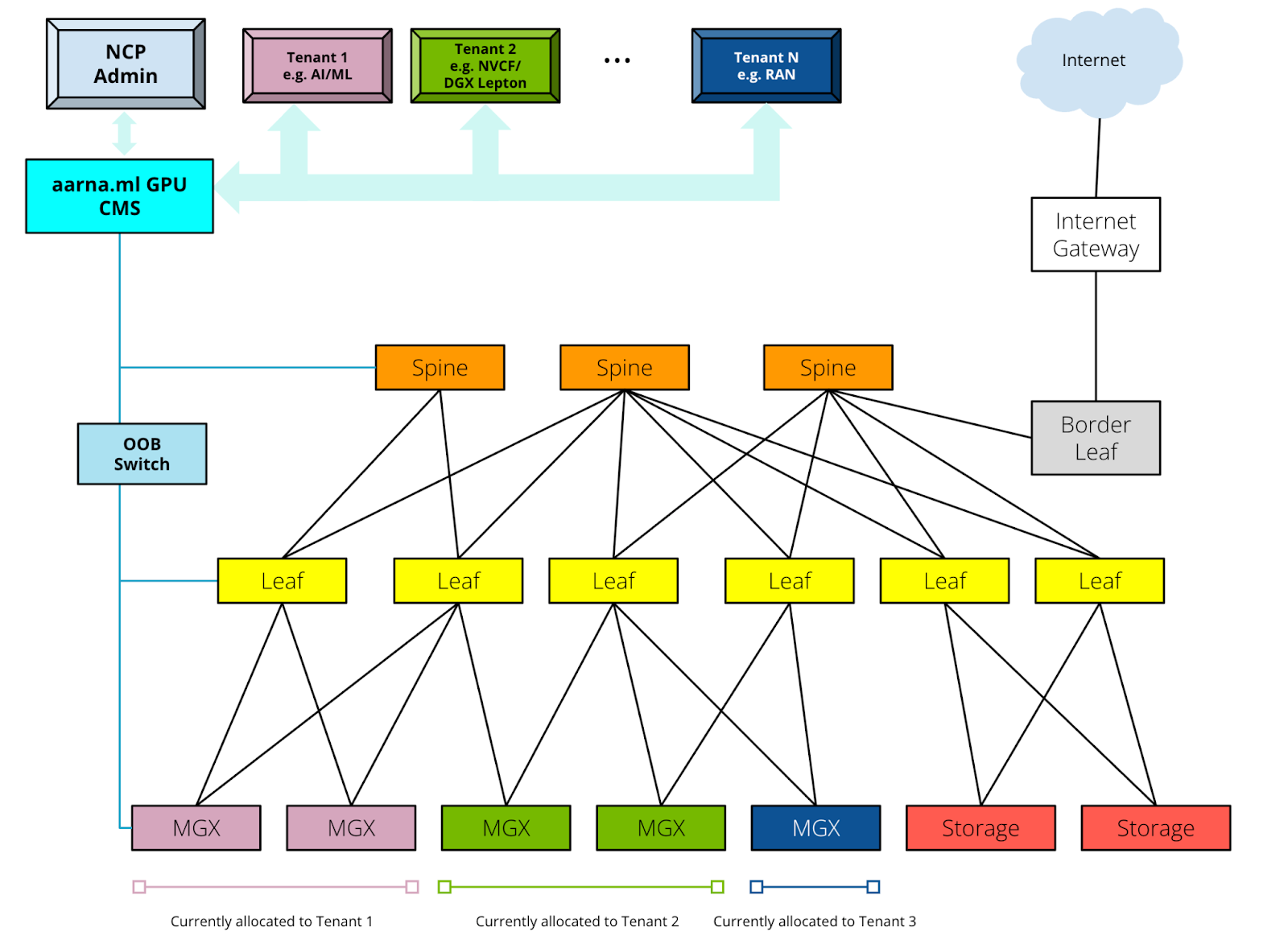
The components for this architecture are:
- NVIDIA MGX servers with NVIDIA Bluefield-3 DPU or CX7 ethernet card
- NVIDIA Spectrum switches for communication (East⇔West and North⇔South)
- NVIDIA Spectrum switches for OOB Management
- NVIDIA AI Enterprise (NVIDIA NIM, NVCF)
- Optional NVIDIA Quantum Infiniband switches for East⇔West communication
- External High Performance Storage (HPS) from partner solutions
- aarna.ml GPU Cloud Management Software (CMS)
- Other components from the local IT infrastructure, such as External Gateway, DNS server etc.
Installation - The infrastructure is installed at the distributed edge→core locations, along with other software components including the aarna.ml GPU CMS, and all the hardware related tests are performed, before onboarding the resources to the aarna.ml GPU CMS.
Onboarding - Once this is completed, the site administrator (Admin Persona) discovers (or onboards) the infrastructure using aarna.ml GPU CMS, and creates the underlay network using the Spectrum switches and the network adapters or DPUs on the MGX servers. The Admin then goes on to create tenants, which are the logical entities that run different types of workloads (RAN or AI) on the same physical infrastructure. The tenants are allocated resources which could be one or more MGX servers, or a fraction of a server or NVIDIA GPU with a virtual machine, along with any additional external storage.
Isolation -The important consideration while allocating these resources is that they need to be fully isolated, so that each tenant’s workload can run without any performance or security implication from other tenants and there is no “noisy-neighbour” situation. The aarna.ml GPU CMS ensures this by providing hard multi tenancy at all levels - CPU, GPU, memory, network adapters, network switches, internal and external storage, all the way to the external gateway.

The aarna.ml GPU CMS functionality does not end there. It also creates fully isolated and configured Kubernetes clusters using upstream software or commercial solutions like RedHat Openshift with all the required K8s controllers such as NVIDIA GPU operators deployed on these clusters, in a per-tenant manner. This way each cluster can have its own set of dedicated resources, which are their master and worker nodes with the associated GPUs.
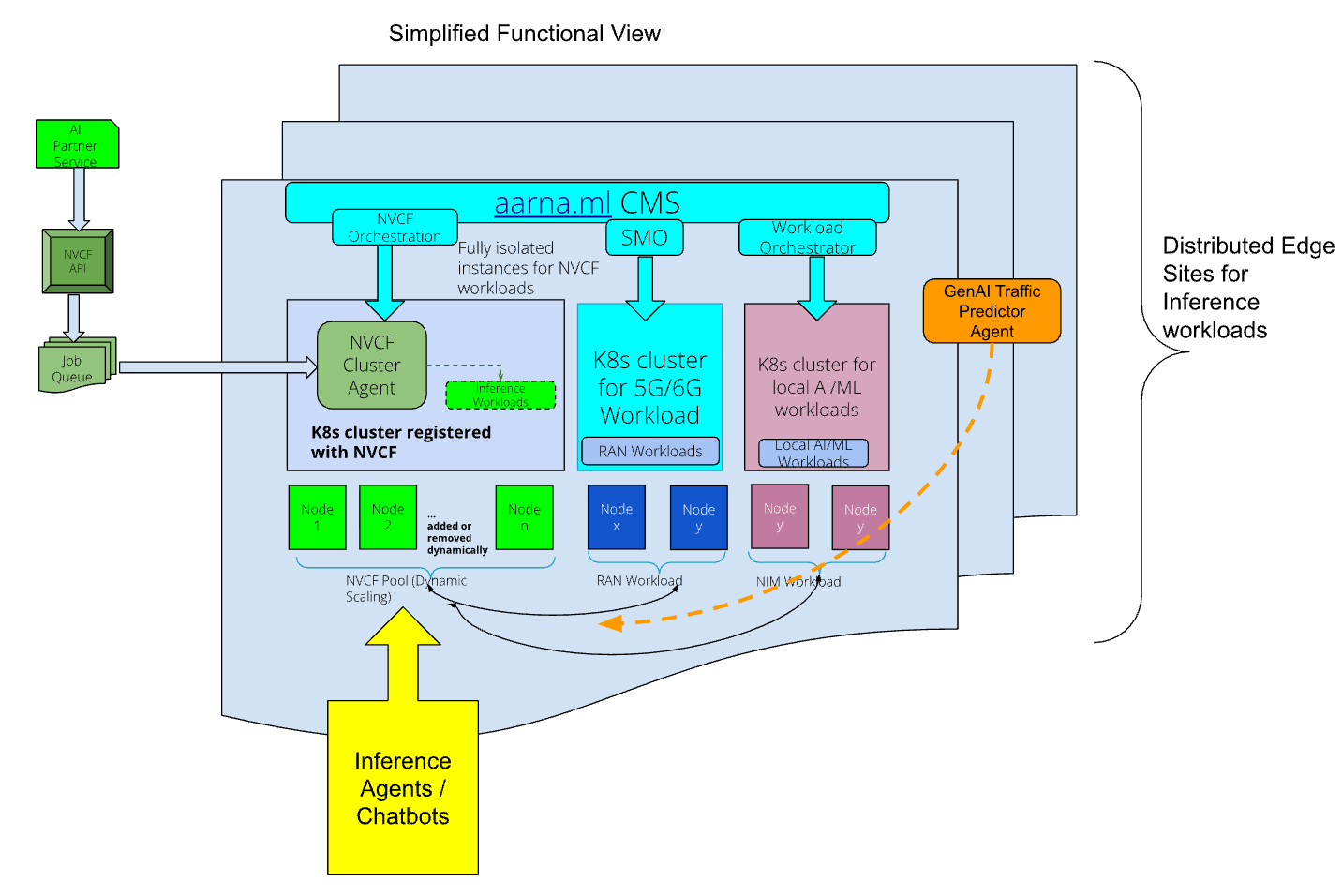
Deploying Workloads - The Admin can then use these per-tenant resources to run various workloads, with guaranteed performance and security. These workloads include 5G/6G functions, which require GPUs for acceleration. These are RAN Distributed Unit (DU) components that can utilize the NVIDIA Aerial CUDA-Accelerated RAN to accelerate their L1 functionality using the GPUs. Managing the RAN DU brings with it additional complexity such as managing the RAN Service Management and Orchestration software, configuring front-haul switches, and configuring the PTP (Precision Time Protocol) Grandmaster. These functions are also performed by the aarna.ml GPU CMS.
This architecture also allows for another key capability - A distributed User Plane Function (UPF) to be deployed at the edge on this infrastructure, allowing local break-out (LBO) of the AI traffic thereby enabling low latency AI applications such as VSS and Agentic AI with low latency and high quality of service
The Admin can expose some of the GPU capacity to running AI workloads. This can be done in two ways:
- Using the aarna.ml GPU CMS, the Admin can create one or more fully isolated Kubernetes clusters, and register these clusters with NVCF. The NVCF service (add some reference here) can schedule distributed Inference jobs on these clusters.
- Alternatively, using the aarna.ml GPU CMS, the Admins or the Tenants, can schedule any cloud native Inference (using NIM functions) workloads on these fully isolated Kubernetes clusters using the application catalog.
Dynamic Scaling - The Kubernetes clusters that are registered with NVCF, or those used by other tenants for AI/ML workloads, can be dynamically scaled-out (by adding more worker nodes with GPUs), or scaled-in (by removing existing worker nodes)2. This process can be automated by a policy engine in the aarna.ml GPU CMS, which can be programmed. As an example, a policy can query the a GenAI model that can predict the RAN traffic patterns, and based on its recommendation, the aarna.ml GPU CMS can scale-in the cluster that is running RAN workloads, and add the resulting worker nodes (after re-provisioning them if needed) to the NVCF cluster. This will automatically expand the cluster use for inference workloads during the off-peak periods of RAN traffic, and perform the reverse operation when the RAN traffic starts increasing.
In both the cases, the aarna.ml GPU CMS also takes care of providing external connectivity to these Inference end-points, by creating the necessary infrastructure using other equipment such as external Gateways, L4 Load Balancers and Firewalls. This entire process is done dynamically, with all the security considerations, without any need for manual intervention. As an example, the Inference end-points can be exposed using DNS names, which map to the Public IP range that is available for this Edge->Core locations. There may be a need for further translation of the Public IP for the internal IP of the cluster, in addition to configuring any site-specific Firewall rules and security groups. All of this functionality is done in a seamless manner, without any need for manual intervention.
This functionality is depicted as below:
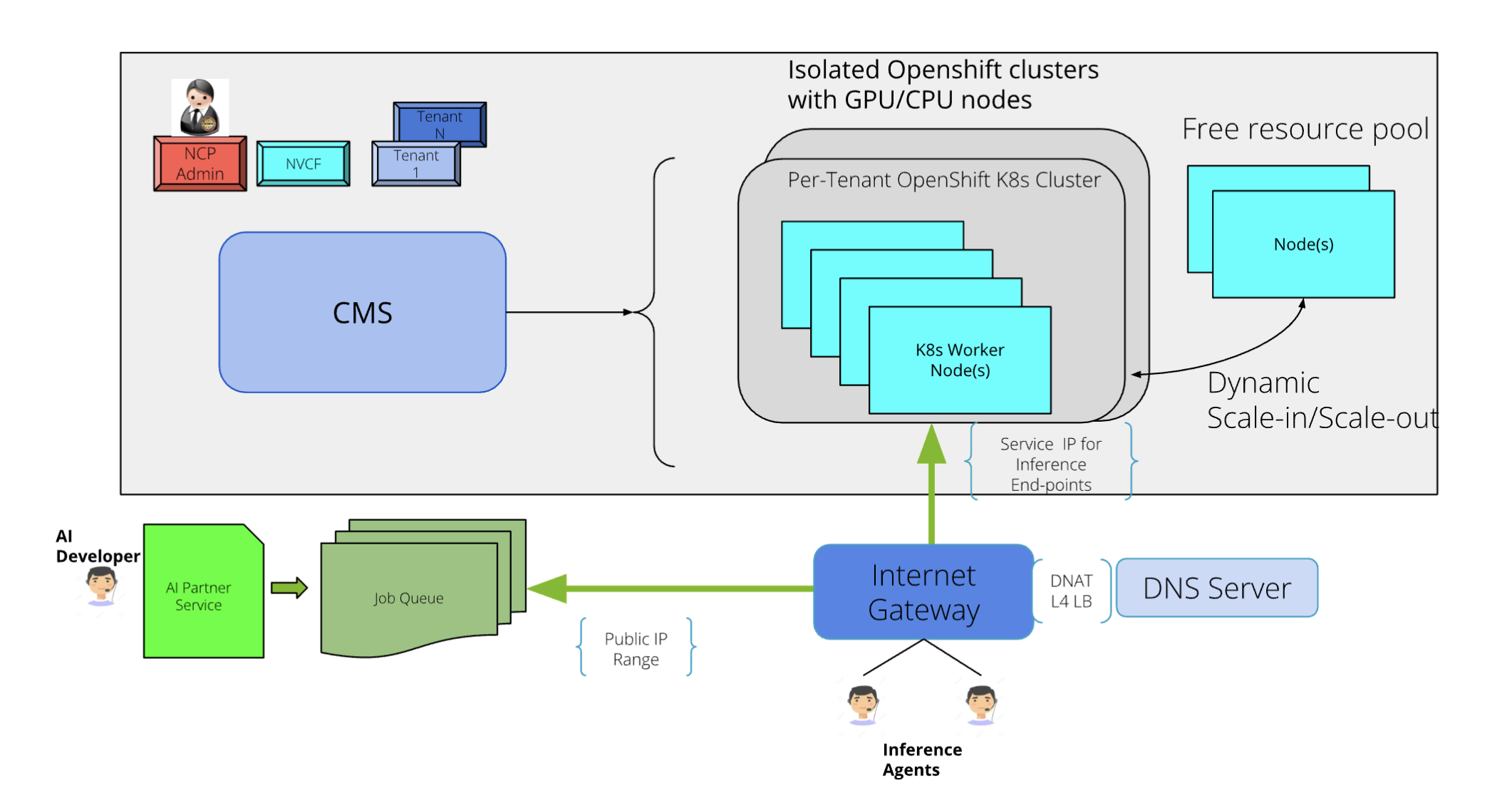
This approach enables all the edge→core locations to fully utilize their GPU infrastructure, without compromising the security and performance of shared resources. The aarna.ml GPU CMS guarantees the isolation while maintaining the performance and maximizing utilization.
“Distributed inference at the edge demands high performance and seamless orchestration across multiple workloads and sites. Aarna.ml’s GPU Cloud Management Software integrated with NVIDIA’s edge AI platforms enables operators to fully realize multi‑tenancy and dynamic orchestration across any workload from RAN to AI to dUPF, and across any cluster, while maintaining strict performance and security guarantees. By working with partners like aarna.ml, we’re helping organizations accelerate time‑to‑market and unlock new revenue streams from distributed AI”, said Soma Velayutham, VP Telecoms and AI, NVIDIA.
Conclusion: The Path to Scalable, Multi-Tenant, Distributed AI
The next wave of AI adoption depends on pushing inference closer to where data is generated—at the edge. Achieving this requires more than raw compute; it calls for an architecture that delivers secure multi tenancy, dynamic scaling, high utilization, and seamless integration with cloud-native AI services. NVIDIA MGX servers, combined with Spectrum-X networking and NVIDIA AI Enterprise, provide the performance and flexibility needed for distributed Edge deployments. Layered with aarna.ml GPU Cloud Management Software, organizations gain the management and orchestration capabilities essential for turning this distributed infrastructure into a scalable, revenue-generating service.
For telcos, this reference architecture offers a blueprint for delivering edge AI that is cost-efficient, flexible, and future-ready enabling AI-RAN deployments. By unifying AI workloads with telecom network functions such as 5G/6G RAN, it maximizes hardware efficiency while enabling new high-value services.
The opportunity is clear: distributed inference is becoming central to how next-generation AI will be delivered. Now is the time to explore, pilot, and engage with NVIDIA and aarna.ml to unlock these capabilities and be part of the ecosystem shaping the future of AI at the edge.
Contact us at info@aarna.ml to discuss further.
1 MarketsandMarkets. (2025, February). AI Inference Market worth $254.98 billion by 2030. PR Newswire; GSMA Intelligence. (2025, March). Distributed inference: AI adds a new dimension at the edge. GSMA Newsroom; Market.us. (2025, January). AI Inference Server Market Size, Share | CAGR of 18.40%. Market.us Research Report.
2 Scaling K8s clusters is completely different than autoscaling workloads where the number of pods are scaled in response to application requirements



